I’ve recently posted a short collection of analyses about the state of collaboration on articles posted to LSN subject matter e-journals: https://ssrn.com/abstract=3206555. I’ll spin out a few parts of the report here over the next few weeks.
The first aspect of the collaboration and rankings analysis I’ll to dig into a bit is the role that rankings play in assembling teams. The findings here (see figure below) show that there’s a tendency for authors to prefer collaborating with individuals who are affiliated with a similarly-ranked institution (the data here excludes authors at the same institution). The spike we see in the lefthand side of the blue distribution shows the strong tendency for individuals to team up and write with others who are at an institution within 10 spots of one’s own school on the U.S. News rankings.
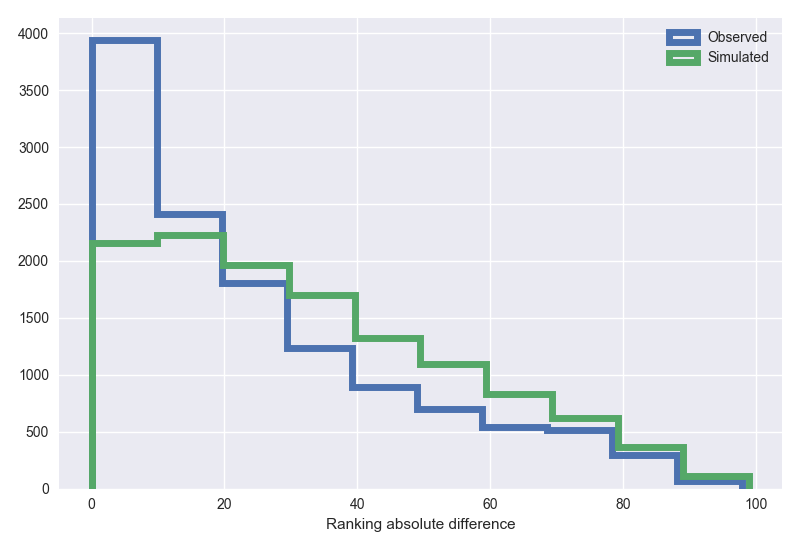
The green distribution is essentially a null model where I’ve re-wired the collaboration network at random, and measured the rankings difference we would see if scholars chose their co-authors at random. This helps demonstrate the systematic, non-random, nature of the observed ranking similarity tendency.
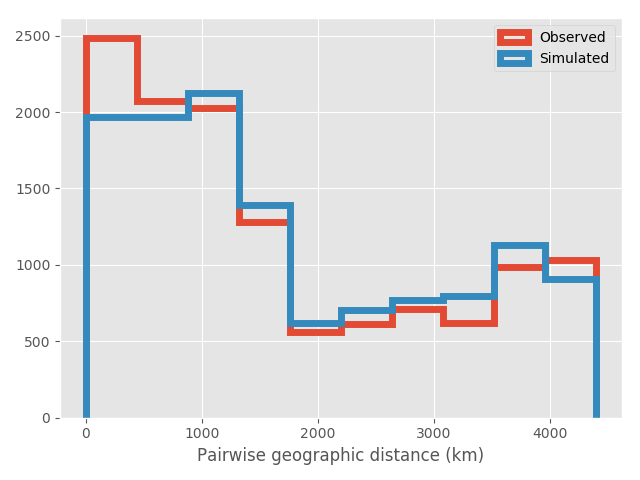
To ensure that the geographic distribution of law schools wasn’t affecting results, in addition to ranking distances I also looked into the distribution of actual distances (see Figure below). Here we do see a slight tendency for authors to prefer collaborating with individuals working at nearby schools, but the preference is relatively minor. I also couldn’t find any relationship between geographic distance and ranking, suggesting that geographic clustering isn’t driving the above observed tendency towards ranking homophily.
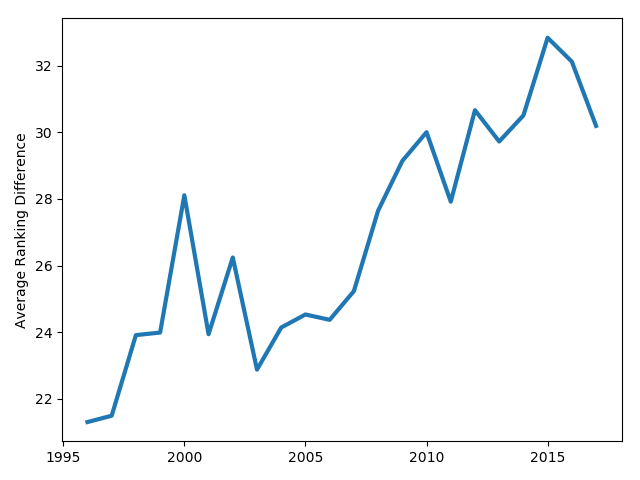
This preference for co-authors at similarly-ranked institutions has been decreasing over time. In the late 1990s, the average pairwise ranking difference was in the low 20s. That number has increased to the low 30s in recent years.
The natural question this raises is why. Why do scholars have a tendency to prefer co-authoring with those affiliated at similarly ranked institutions? There are a number of plausible (not mutually exclusive) explanations, most of which are difficult to test:
- They are more likely to interact with others at similarly-ranked institutions in social and professional situations – e.g. they are more likely to present at the same symposia – and thus more likely to know one another (the social awareness hypothesis)
- They are more likely to suggest collaborating with individuals at similarly-ranked institutions (the tentative asker hypothesis)
- They are more likely to agree to suggested collaborations when those suggestions come from someone working at a similarly-ranked institution (the tentative accepter hypothesis)
- Collaborations between individuals at similarly-ranked institutions are more likely to successfully conclude the project and draft a paper (the team effectiveness hypothesis)
One thing I was able to look into was the relationship between ranking difference and impact. Impact here is measured as downloads/day since the article was published. Once we control for things like the size of the team and the highest-rank of any school represented on the team, we see no real relationship between a team’s ranking difference and its research impact.
Ultimately, I have no solid answers for the questions raised by the observation that scholars seem to prefer collaborating with others at similarly-ranked institutions, but I do find it interesting.
| Model 1 | Model 2 | Model 3 | |
| Intercept | -0.7379 ***
(0.0012) |
-0.8509 ***
(0.023) |
-0.6652 ***
(0.02) |
| Ranking Difference | 0.0012 ***
(0.001) |
-0.0009
(0.001) |
-0.0011
(0.001) |
| Team Size | 0.0481 ***
(0.004) |
0.0427 ***
(0.004) |
|
| Highest Rank | -0.0109 ***
(0.001) |
||
| Pseudo R2 | 0.00002 | 0.007 | 0.02 |
| DV = binary measure of downloads/day, 1 = above the 75th percentile
N = 22,635 *** p < 0.0001 |
|||